When the most recent version isn’t what you need or want.

In general, you cannot.
Particularly with media files (like music or video), if a webpage changes its contents, whatever was there before is removed from public access.
However, there are a couple of things to try.

Old versions of webpages
Archive.org and search engine caches are two straws to grasp at when looking for older version of webpages. Unfortunately, there’s no guarantee that what you’re looking for will be found in either.
Archive.org
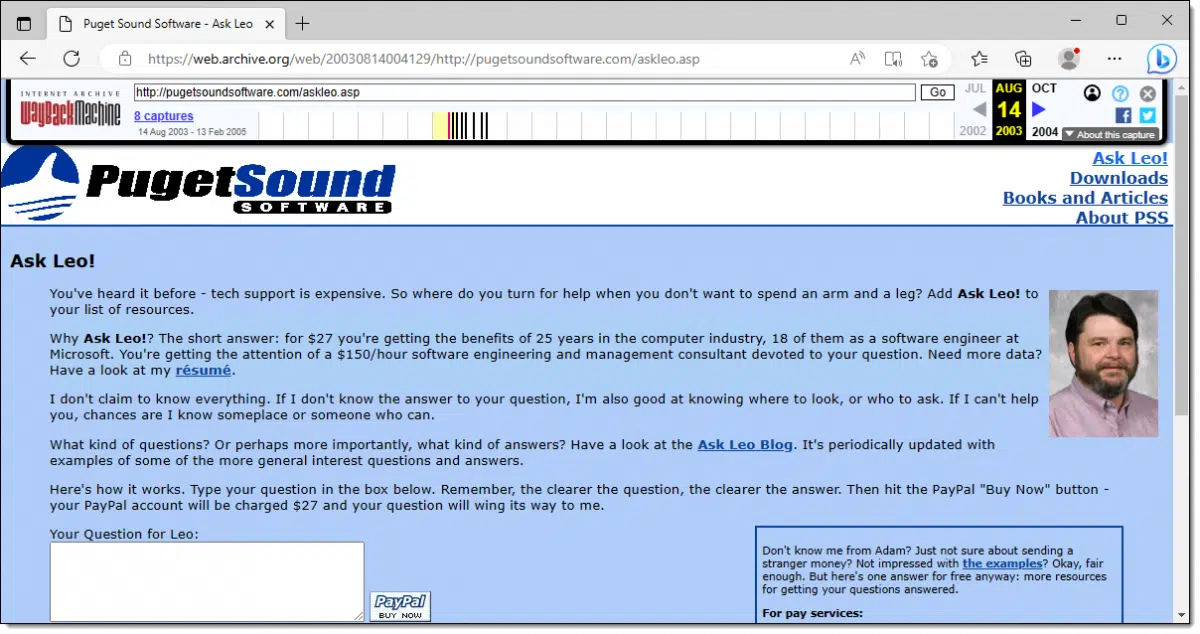
The Internet Archive at archive.org offers the Wayback Machine, which lets you access archived copies of websites from the past.
The problem with the Wayback Machine, however, is that not all sites are archived, and not all archives are updated frequently. You may or may not find a copy of the site as of the date you care to see.
An additional problem is it’s not uncommon for media — audios, videos, images, and the like — not to be archived for a variety of reasons.
And, of course, website owners can “opt out”, meaning that they instruct archive.org not to archive their site.
As an example, at the top of the page is an image of Ask Leo! as of August 2003, courtesy of the Wayback Machine.
Most, but not all, of the links on the archived page even work.
Archive.org might be a place for you to start.
Help keep it going by becoming a Patron.
Search Engines
Many search engines — most notably Google — may make available a “cached” copy of webpages they return in search results. (Click the ellipsis next to the search result, if it’s there, and then look for “cache” in the additional information displayed.)
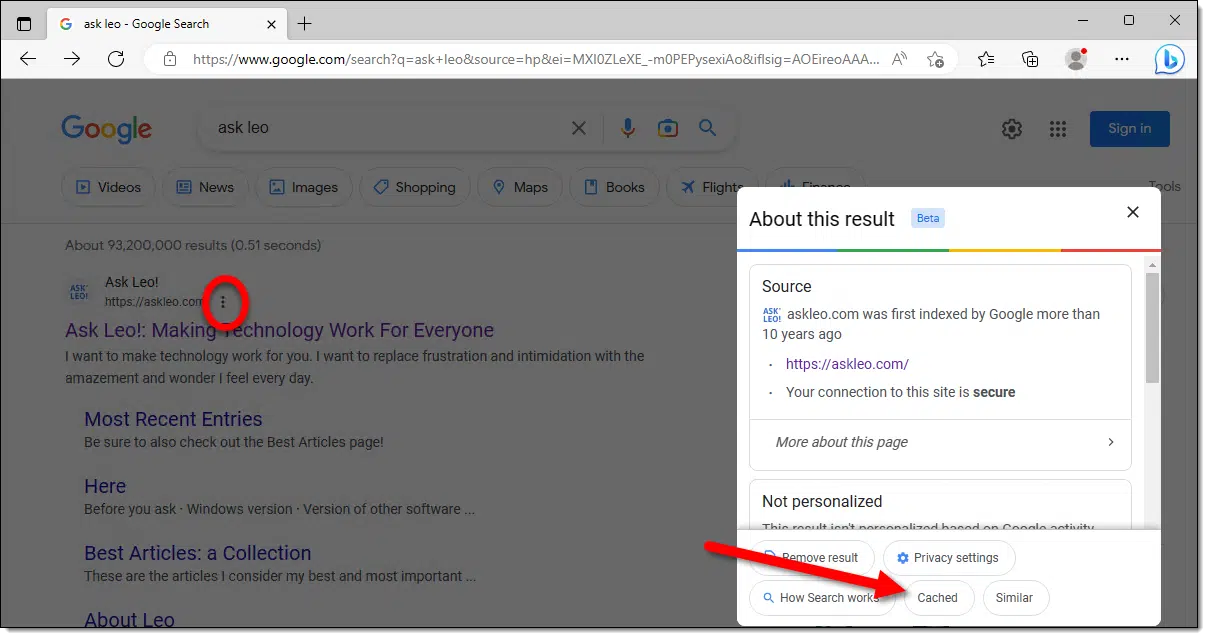
The problem here, however, is that cached copies are usually only the copy as of the most recent visit by the search engine indexer. Depending on the site, that could be anything as recent as a few hours, weeks, or more. If they haven’t updated their cache since whatever you were looking for was there, you might be able to find it. In the example above, a cached copy of the Ask Leo! homepage was one day old.
But once again, the cache focuses on webpages, rarely includes media such as audio or video, and can be discouraged by the website owners.
Do this
We often say that once you post something on the internet, it’s there forever. This certainly seems to apply to embarrassing photos, misstatements of truth, captioned cat pictures, and pretty much anything else that we might wish would go away.
On the other hand, it seems situations such as yours are common as well: things we remember finding on the web disappear.
Either way, what remains on the web — permanently or briefly — remains out of our control. The tools above may help you find some things, but not necessarily everything.
My newsletter is still around! Subscribe to Confident Computing! Less frustration and more confidence, solutions, answers, and tips in your inbox every week.
Podcast audio

Related Video



“We often say that once something is posted on the internet, it’s there forever. This certainly seems to apply to embarrassing photos, misstatements of truth, captioned cat pictures, and pretty much anything else that we might wish would go away.”
That’s because the Internet or more specifically the Web is subject to the basic laws of the universe, Murphy’s Law being the law most applicable. “Any thing that can go wrong will go wrong.” That’s why everything old you want to find on the web is gone and anything you wish would go away (compromising or embarrassing photos, for example) will stay forever. 🙂
The Wayback Machine is an initiative of the Internet Archive, a 501(c)(3) non-profit, building a digital library of Internet sites and other cultural artifacts in digital form. Other projects include Open Library & archive-it.org. I just retrieved a site I deleted 20 years ago.
Also: http://archive.is
The wayback machine is amazing. If you know the url of a site that no longer even exists, it can frequently been found there.
Wow! Excellent!! Keep up the good work Leo!!! 🙂
If you use Firefox, you can install the MAFF (Mozilla Archive File Format) add-on that will allow you to save web pages in a compressed file format (MAFF or MHTML) on your computer so you can view them later. The web pages are stored in a single compressed file which you can open later with ctrl-o, then selecting the file.
I use this frequently to save web pages I am interested in, or have not had time to finish reading. I save them immediately.
Doesn’t this sound familiar? Like backing up? Don’t trust someone else to do it. Make your own web archives.
I used to use internet explorer and set the cache to keep data for 999 days. If something from the past is needed I can open it from the cache. Sometimes some editing is needed. The Firefox cache is compressed, I have not figured out how to circumvent that.
This is the reason to print or copy to your computer something from the internet you are interested in keeping. The more important you find something, the more likely it is that somebody will change it, move it or erase it.
Just saving web page links is fine, until somebody cleans out the server and deletes the page that link leads to. Not all servers have what seems to be unlimited space and older stuff is often removed so new stuff can be posted. The other thing that happens is that the company or person that placed the item in the internet can go bankrupt, die or just stop maintaining the server they posted stuff to.
I’d use Windows Live Mail from Windows essentials for years but when I updated to W10 it was the only install program I hadn’t saved (I have a folder called installed). MS had stopped providing it as a download!
So the Wayback Machine was my saviour.
John
I mostly use the Internet Archive to recover old DOS games I used to enjoy, including the likes of Mario and Commander Keen. I use DOSBox to run the games. It works very well. Nostalgia can be a wonderful thing.
My2Cents,
Ernie