OCR, an acronym for Optical Character Recognition, is a process that converts a picture of text into actual, editable, text.
For example, you might find a picture of a meme on social media, which may be nothing more than text on a nice background saved in an image format, such as .jpg. Or you might scan a document you’ve received, which often results in a series of image files, or a PDF containing a series of images — “pictures”, if you will, of the individual pages.
Rather than retyping that text by hand to use elsewhere, you can use OCR to automatically extract the text for you.
As it turns out, Microsoft OneNote, present in Windows 10 and Microsoft Office, has basic OCR capability built in.
The image
OCR starts with an image. That image — most commonly in “.jpg” or “.png” format — contains text you want to be able to use in some other context without having to re-type it all.
OCR is a computer analysis of that image. However, the analysis to identify individual characters can make mistakes. Even though OCR has improved as computers have become more powerful, it still introduces errors into its results.
There is a single, simple characteristic of text in an image that determines how accurate OCR will be: its clarity. The clearer the text, the more likely OCR will succeed. If the letters are small and fuzzy, OCR has a difficult time determining exactly what characters they are. This often results in visually similar characters being confused with one another — the letter “l” and the number “1” being a good example.
Clarity can mean that the text is large, or it can mean that smaller text is very crisp. In either case, or somewhere in between, the more clear the text is in the original image, the more accurate the OCR results will be.
OCR in OneNote
I’ll start with this image:

That’s a fairly typical example of an image that might be posted to social media as a “meme” in hopes of being shared a lot. It’s simply text on a background saved as an image — in this case, in”.jpg” format. Since it’s an image, you can only click on the whole image, perhaps to copy it, but you cannot click on and select only the text within it.
To extract the text from the image, we’ll start by opening the jpg file in a photo-viewing or image-editing application. Any will do, as long as it supports copying the image to the clipboard. There’s a good chance that simply double-clicking the image file in Windows File Explorer will open it in a suitable application. Since Paint 3D comes with Windows 10, I’ll open it in that.
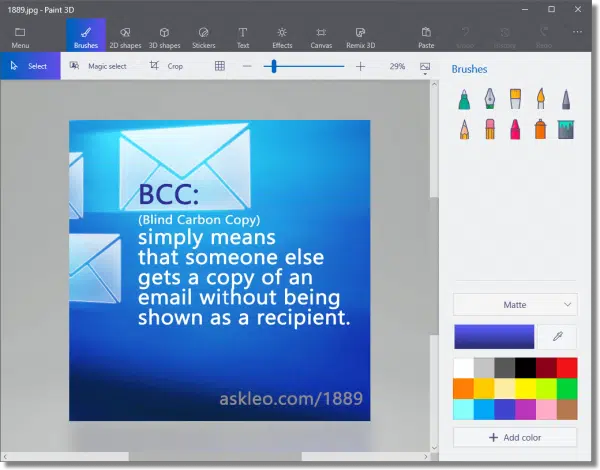
Now, copy the image to the clipboard. In Paint 3D, I’ll type CTRL+A to select the entire image, and then CTRL+C to copy the image to the clipboard. Again, any application or technique you use to copy the image to the clipboard should be just fine.
Now, open OneNote, and create a new note or open an existing one. Click inside the note and type CTRL+V to paste the image from the clipboard into your OneNote note.
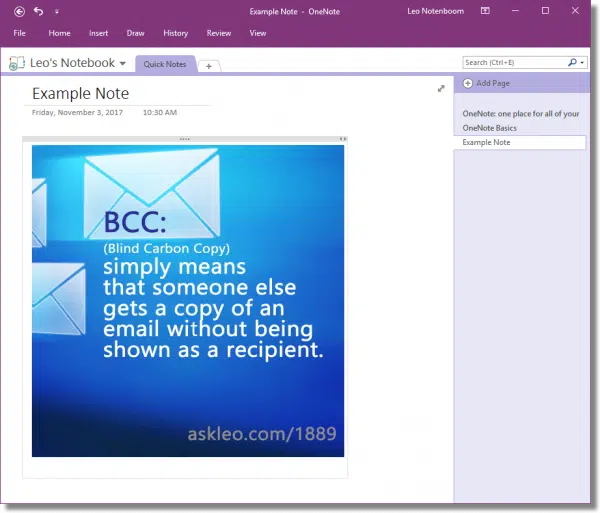
Now, right-click on the image and click on Copy Text from Picture.
Even though nothing will appear to have changed, this is where the magic happens. 🙂 OneNote has analyzed the image, identified the text displayed in the image, and placed a copy of that text into the clipboard.
Run your favorite text-processing program, such as Microsoft Word, WordPad, or, as I’ll use below, Notepad. Once the program is open on new document, type CTRL+V to paste the contents of the clipboard into your document.

You can see above that the text that was part of the picture has been placed into Notepad.
You’ll note there’s no formatting — no bold or italics, size changes, or anything else — just text. Depending on the original, line breaks may be preserved.
After reviewing the accuracy of the text as compared to the original, you can then do whatever you like with it, such as pasting it here and formatting it a little:
BCC:
(Blind Carbon Copy)
simply means
that someone else
gets a copy of an
email without being
shown as a recipient.
askleo.com/1889
This article is the result of a Tip Of The Day suggestion made by reader David Phipps. It just seemed a little more than a “tip”. 🙂
Do this
Subscribe to Confident Computing! Less frustration and more confidence, solutions, answers, and tips in your inbox every week.
I'll see you there!


I switched from Evernote to OneNote when Evernote wanted to charge me to synchronize my devices. OneNote does everything I need, and with this OCR feature, it’s definitely superior for my purposes.
And if you want to OCR a picture with text on a web page, you can simply right-click on the image and select “Copy image” or its equivalent in your browser without the need to use a picture editor to copy the image to clipboard.
It does NOT work!
No option for ‘Right-click on the image and click on Copy Text from Picture’.
OneNote version 17.8730.20741.0
Maybe this article should be updated?
It works in Version 14.0.7190.6000 (64-bit) from Office 2010.
no option ‘copy text from picture’ for me either.
There is also a download called FreeOCR which does the same thing without one having to add another lifeline to Microsoft. Find it on Google
Thanks so much for this. It just saved me having to buy Adobe PDF transfer to Word for another year.
I only just discovered that opening a ‘picture’ pdf (i.e. a scanned text document) using Word seems to do much the same, in other words produces unformatted and imperfect – but still useable – text.
Presumably the advantage of OneNote is that it can do the same with true pictures.
This is also great for extracting the text from an error message in Windows.
Did everything this article says, will not work in my OneNote (version 17.8730.20741.0). No option for ‘Right-click on the image and click on Copy Text from Picture’. So, no OCR for me here. Really wonder why.
Thanks Leo. It worked easily for PDF files. One Note simply captured the text. When trying a JPG file, I copied the photo containing text and pasted it into three different photo display apps and then into One Note. However, the “Copy Text from Picture” feature was not available. Maybe I’m using the wrong/ old One Note.
No need to post this, maybe just a private reply to straighten me out…
Sam,e here. I tried copying a png and then did it with a jpg image version, but the pasting and right clicking gave me no picture to text options at all. One Note Version 17.8730.20741.0.
Wish I’d read the comments before wasting so much time on this. I had the same problem as Bjorn and SteveL. Using Version 17.8730.20741.0, I had no option for Copy Text from Picture, only Copy. Any ideas?
This will not work with the version noted above but I used One Note that came with MS Office 2010 and it did. I also switched the image viewer to Fastone (Leo has mentioned this before as a great image viewer (free) and it is. The Paint 3D image viewer did not work as far as I could see. I searched for the OCR in One Note as specified in this article and a lot of people had the same problem with the One Note that came with Win10 versus the One Note that is a part of MS Office.
The version for One Note that worked is 14.0.7162.5000
Years ago … our good helper LN seems to be a bit outdated this time 😉
The old OneNote 2016 has this extremely useful feature. The new OneNote does not. For me, this is reason enough not to “upgrade.”
I’m sorry to say you’re right. I bought a new computer a couple of days ago and it came with Office 365. The OneNote program does not have the right-click OCR feature. Very disappointing. I found some websites describing how to revert to an older version and get the OCR back, but the disadvantage is that I would have to disable updates. I also found that the newest version of Microsoft Word contains the OCR feature. That might be why they deleted it from OneNote. In Word, past a picture, right click the picture, click Edit Alt Text. That bring up a little window containing the text content. Press Ctrl-A to select all of the text. Right click the highlighted text and click Copy. Then paste the copy anywhere.
I had OneNote 2003 which doesn’t have OCR. So after reading your tip, I got OneNote 2007 – two copies (from Amazon), so I could install it on my main laptop and on my old laptop next to my scanner. It took several days to get the kinks worked out; you need OneNote Service Pack 3 for the OCR to work well, for example. But I am just thrilled with it!! I scanned a 1977 press release on yellowed paper, and OneNote OCR’d it beautifully, with only two trivial errors in the whole thing. THANK YOU so much, Leo, for posting this tip! (OneNote 2007 12.0.6606.1000 is the version)
Update: OCR was removed from both Microsoft Word and Microsoft OneNote but has been restored to OneNote. I got into a chat today with Microsoft support. They confirmed that the function was not in Word but the tech reinstalled OneNote with what she said is the latest version. She said my version was not the latest (although Office had done an automatic update a few days before. The latest version of OneNote has the OCR function back. Hooray. (The short-lived word version was non-great.)
Used one note ocr on a pdf. Copied editable text from one note to word. Can’t copy/paste pieces of word document. Any ideas?
What does “can’t” mean? How does it fail?
I’ve been trying to get that fancy right click option in Office 2019. It doesn’t appear. After reading the comments above, I see why. It only works in older versions.
I now use FreeOCR. It’s a little more versatile than the OneNote OCR feature was.
I actually use Google Docs for this these days. I should write that up.